



週刊エーアイElithでは、株式会社Elith(エリス)によって運用される日々の機械学習のニュース・OSS・研究・技術・学会・国内外AI企業の情報を毎週月曜日に配信するニュースレターです。 ニュースレターのコンセプトや概要、対象者、読み方については下の記事をご覧ください👍
AIニュース
AIニュースでは1週間でトレンドとなったニュースを紹介します。
2023年5月21日から2023年5月28日までのAIトレンドのニュースです。
AI資金関連ニュース
AI資金関連ニュースでは1週間でトレンドとなったニュースを紹介します。
2023年5月21日から2023年5月28日までのAIトレンドのニュースです。
ChatGPTのサム・アルトマン氏ら開発「Worldcoin」が約160億円の資金調達、Blockchain Capital主導で
東大発・米国物流ロボティクスベンチャーRENATUS ROBOTICS Inc.、200万ドル(約3億円)の資金調達を実施し、シードラウンドをファーストクローズ
論文
今週は、PEARL: Prompting Large Language Models to Plan and Execute Actions Over Long Documentsについて解説します。
Abstract
大型言語モデル(LLMs)は長い文章を入力することが困難です。長い文章を理解する手法としてchain-of-thought promptingなどが精度を改善します。
しかし、モデルの入力テキストはトークン化されますが、アーキテクチャーの都合上モデルの入力トークン数に制限があります。
長い入力文書を理解するために、分解と各中間ステップ(長い文章を理解するための3つのステップ)の出力が非常に困難であることが明らかになっています。
本研究は、長い文章を理解するための複雑な推論タスクにおいて、大型言語モデル(LLMs)の性能を向上させるための戦略として、中間ステップに分解することで入力例を改善する「PEARL」というフレームワークを提案します。
中間ステップは、
アクションマイニング:要約、検索など
プラン生成:アクションの実行するプラン
プラン実行:2で生成したプランを実際に実行する
という3つで構成されます。
PEARLはQuALITYというデータセットを用いて評価を行いました。PEARLは、ゼロショット とchain-of-thought promptingを上回りました。また、アブレーション実験(一部を除く)では、PEARLの各ステージが性能に重要であることがわかりました。
Introduction
例として以下のような質問を想定します。
この質問はQuaLITYデータセットに含まれる”Breakaway”というストーリーに基づいています。
ストーリーの初めの会話と最も繋がる最後の文章の部分は何ですか?この質問に回答するために、以下のようなアクションが必要になります。
最初の会話の登場人物の把握
最初の会話の要約
最後の文章の主題やイベントの要約
最後の文章の会話の役割
最初の会話と最後の文のつながりをランク付け
このような複雑なタスクをこなせるフレームワークがPEARL(Planning and Executable Actions for Reasoning over Long documents)です。
以下がアクションマイニング、プラン生成、プラン実行の例です。

関連研究
LLMの能力は、インストラクションを導入することで精度が改善してきた (Brown et al., 2020; Zhang et al., 2022; Touvron et al., 2023)
フィードバックを導入することでより人に近い文章の生成が可能になった(Stiennon et al., 2022; Ouyang et al., 2022; Chung et al., 2022)
chain-of-thoughtなどのプロンプトが登場し、モデルの理由付け能力が大きく改善した
課題を分解する手法 (Press et al., 2022; Dua et al., 2022; Khot et al., 2023; Yao et al., 2023b)、自己修正機能 (Huang et al., 2022; Shinn et al., 2023; Madaan et al., 2023)、プランニング (Yao et al., 2023a; Wang et al., 2023a; Long, 2023)などのプロンプトテクニックにより精度が大幅に改善した
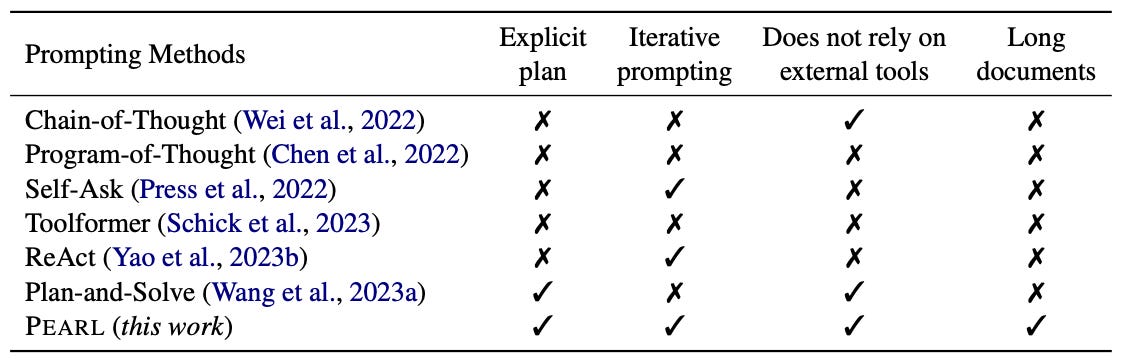
以下の表は、プロンプトメソッドの比較表です。
明確なプランニングをし、長い文章を理解できる手法は本手法のPEARLのみです。
PEARLの手法
ほとんどの理由付の手法は、長く複雑な文章を扱うことができません。PEARLでは、3つの中間ステップを用いて回答を得ます。
1.アクションマイニング
PEARLでは、外部のAPIを使わずに学習データセットからアクションを生成します。
最初はデモに使うために少数のアクションを手動で生成します。その後、人が生成したアクションを元により多くのアクションを生成させます。
以下がその例です。
Seed actionsのSUMMARIZE(CTX)関数はCTXという文章を入力すると、要約内容が返される関数です。
Instructions and demonstrationsでは、質問が入力された時に、新しいアクションを生成するように設定します。
Input questionで”What is the alien’s mission?”という質問に対して、FIND_MISSION(CTX, X)という関数が生成されています。

2.プラン生成
プラン生成では、アクションマイニングで生成されたアクションを使って、回答を得るためのプランを生成します。
Mined actionsがアクションマイニングで生成されたアクションです。
Instructions and demonstrationsでは、回答を得るためにプランを生成するように指示するプロンプトです。
Input questionの質問に対して、アクションを使ったプランが生成されます。

3.プラン実行
上記のプランを実行するステップです。
Instractionsにアクションの定義、現在のアクション、過去のアクション履歴を記載することで最終的な出力を得ることができます。

4.自己修復・強化
LLMによって生成されたプランは、不正確なフォーマットであったり、質が低いことがあります。これを改善する方法が、自己修復(self-correction)と自己強化(self-refinement)です。
自己修復はプラン実行前に、自己強化はプランをモデルに組み込む前に実行されます。
プランがフォーマット通りでなければ、エラーメッセージを出力します。そのメッセージをLLMに入力することで、フォーマット通りの出力を得ることができます。
実験
本実験は、QuALITY QA datasetを使い実験を行いました。1KのデータセットをLongとShortに分割しました。本実験は全てはより大域的な文章に関する質問が中心となるため、大域的な質問はLong、局所的な質問はShortとカテゴライズを行いました。
Long:330セット(Q and A)
Short:302セット
実験結果
以下の表が実験結果です。
GPT-4 PEARLはLongのデータセットに対して、最も精度が高いことが確認できます。GPT-4のゼロショットと比較するとその6.6%精度を改善しています。

また以下の図は、生成されたアクションの数と精度のグラフです。アクションの数が一定以上増えると、精度が低下することがわかります。これはアクションに重複が存在したり、似たアクションが多いことなどから、LLMがうまく判断することができなくなることが考えられます。適切なパラメーターの設定が重要です。

まとめ
本研究はPEARLという長い文章の入力を可能にするフレームワークの提案に関する論文を紹介しました。
PEARLにより長い文章では中間ステップの必要性が確認できました。LLMも人間と同じように長い文章を理解する際は、一度情報をまとめてどのような順序で実行するかを明確にすることで精度が改善することができます。