
週刊エーアイElith: Issue #2

週刊エーアイElithでは、株式会社Elith(エリス)によって運用される日々の機械学習のニュース・OSS・研究・技術・学会・国内外AI企業の情報を毎週月曜日に配信するニュースレターです。
ニュースレターのコンセプトや概要、対象者、読み方については下の記事をご覧ください👍

AIニュース
AIニュースでは1週間でトレンドとなったニュースを紹介します。
2023年1月23日から2023年1月29日までのAIトレンドのニュースです。
AI資金関連ニュース
AI資金関連ニュースでは1週間でトレンドとなったニュースを紹介します。
2023年1月23日から2023年1月29日までのAIトレンドのニュースです。
論文
今週は1月6日にMicrosoftによって発表されたVALL-Eについて解説します🧠
VALL-E: Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers
論文からのアブストラクトの引用
音声合成(TTS)のための言語モデリングアプローチを紹介する。具体的には、既製のニューラルオーディオコーデックモデルから得られた離散コードを用いてニューラルコーデック言語モデル(VALL-Eと呼ぶ)を学習し、TTSを従来のような連続信号回帰ではなく、条件付き言語モデリングタスクと見なす。事前学習段階では、TTSの学習データを既存のシステムの数百倍にあたる6万時間の英語音声にスケールアップする。VALL-Eは、文脈内学習機能を持ち、未知の話者の3秒間の録音を音響プロンプトとして用いるだけで、高品質なパーソナライズ音声を合成することが可能である。実験の結果、VALL-Eは、音声の自然さと話者の類似性の観点から、最先端のゼロショットTTSシステムを大幅に上回ることが分かった。また、VALL-Eは、合成時に話者の感情や音響プロンプトの音響環境を保持できることがわかった。
概要
VALL-Eは、1月6日にMicrosoftによって発表された音声合成AIです。
VALL-Eは、わずか3秒の音声のプロンプトを利用することで驚くべき精度でパーソナライズな音声を生成することができます。
アブストラクトによると、既存のシステムの数百倍に相当する6万時間の英語音声を学習したゼロショットのTTSモデルです。
また、アブストラクト中では「合成時に話者の感情や音響プロンプトの音響環境を保持できることがわかった」と記載されており、非常に興味深いです。
昨年末ではテキストから3D点群を生成するPoint-Eが発表されたばかりですが、生成系分野はまだまだ盛り上がりそうです。
技術
モデル
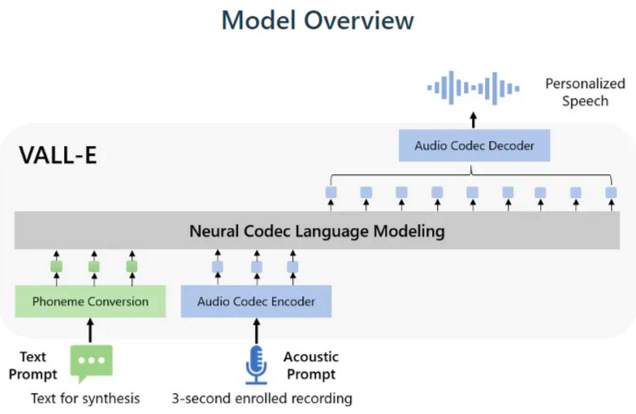
TTSは普段音声AI系の仕事についてない方は聴き慣れない方も多いので説明するとText-to-Speechの略称です。
モデルは図にあるように、テキストのプロンプトに加え、音声のプロンプトを入力することでパーソナライズされた音声を出力することができます。
学習データ
VALL-Eは、Meta社のLibri-Lightオーディオライブラリに収録された7000人以上の話者による6万時間の英語音声で学習されています。
通常の音声合成の場合、数十時間の単一話者データや数百時間の複数話者データで学習することが通常です。いかにVALL-Eのデータ量が多いが理解できるかと思います。
Libri-Lightはノイズを含んだ音声のみのデータです。論文中では、音声認識ライブラリを用いて書き起こしを行ったと書いてありました。
音声合成の研究を少しでも行った方は理解できるかと思いますが、無響音室などで収録された音声合成用のクリーンなデータを用意する必要があります。
VALL-Eは、頑強なモデル構造とデータ量を用いて音声合成性能をアップさせてます。
結果
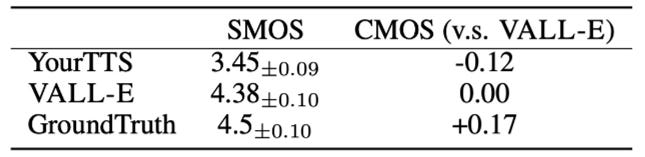
本研究では様々な評価指標でVALL-Eが比較されました。その中でもSMOSとCMOSを用いた評価結果をお伝えします。
SMOSはsimilarity mean option scoreの略称であり、元の話者の音声に似ているかどうかを測定する指標です。SMOSは、0.5ポイント刻みで1〜5までの尺度があります。
CMOSはcomparative mean option scoreの略称であり、音声の自然さの指標です。CMOSは、-3(ベースラインよりかなり悪い)から3(ベースラインよりかなり良い)の尺度があります。
ここで比較されるYourTTSはゼロショットTTSモデルのSOTAです。SMOSは+0.93とYourTTSを大きく上回り、ゼロショットにおけるVALL-Eの有効性を証明しました。
音声の自然さに関しては、VALL-EはYourTTSを+0.12 CMOSで上回り、提案手法がベースラインに対してより自然でリアルな音声を合成できることが示された。
課題
いくつかの単語が不明瞭、見逃し、重複することがあるようです。
参照
機械学習系OSS
機械学習系OSSでは利用者の多いOSSのリリース情報を中心に解説します。
リリース
scikit-learn 1.1.2
2023年1月25日にscikit-learn 1.2.1 がリリースされました!
20個のバグフィックスと1つのAPIが非推奨になりましたが、大きな機能変更はありません。
huggingface/transformers v4.26.0
2023年1月26日にhuggingfaceのtransformersが4.26.0をリリースされました!
こちらは大量の新機能が追加になりました!その中でも気になった機能を紹介します。
ImageProcessorクラス
画像での今までの特徴量生成時の前処理クラスはImageProcessorに名前が変更されました。
このPRなどを見ると分かりやすいと思います。
新モデル
UPerNet
UPerNetは、ConvNeXtやSwinなどのビジョンバックボーンを利用して、画像から様々な概念を効果的にセグメンテーションするためのフレームワークです。
Unified Perceptual Parsing for Scene Understandingの論文中で紹介されたモデルです。
Swinのバックボーンで利用する場合は以下のように簡単に利用することができます。
from transformers import SwinConfig, UperNetConfig, UperNetForSemanticSegmentation
backbone_config = SwinConfig(out_features=["stage1", "stage2", "stage3", "stage4"])
config = UperNetConfig(backbone_config=backbone_config)
model = UperNetForSemanticSegmentation(config)
TimeSformer
TimeSformerのモデルはTimeSformerで提案されました。動画像を認識することができます。
OneFormer
OneFormer は、単一のパノプティックデータセットで学習し、セマンティック、インスタンス、およびパノプティックセグメンテーションタスクを実行できる、汎用的な画像セグメンテーションフレームワークです。
OneFormerはタスクトークンを用いて、フォーカスされたタスクに対してモデルを条件付けることで、学習時にはタスクガイド型、推論時にはタスクダイナミック型のアーキテクチャを実現しています。
技術コラム
技術コラムでは毎回テーマを決めて機械学習に関連する技術を紹介します💻
物体検出のためのバウンディングボックス
バウンディングボックスは、画像上のオブジェクトを示す四角形です。バウンディングボックスは複数の形式があります。今回はpascal_voc、albumentations、coco、yoloの4 つの形式をご紹介します。
4つの形式を紹介する前に前提知識の座標について説明します。画像中の点はピクセルの座標です。ピクセルの座標は、(x, y)の形式で表現されます。画像の左上を(0, 0)の原点とし、xは横軸、yは縦軸として表現されます。画像の右方向にxは増加し、画像の下方向にyは増加します。
pascal_voc
pascal_vocはPacal VOC datasetのデータ形式です。その形式は[x_min, y_min, x_max, y_max]です。(x_min, y_min)は物体の左上のピクセルを示し、(x_max, y_max)は物体の右下のピクセルを示します。バウンディングボックスは[50, 60, 180, 200]などと表現されます。
albumentations
albumentationsのバウンディングボックスの表現はpascal_vocの形式に似ています。しかし、albumentations形式では値を正規化する点が異なります。データ形式は、[x_min_norm, y_min_norm, x_max_norm, y_max_norm]です。画像全体のサイズを(640, 480)とし、pascal_voc形式のバウンディングボックスを[50, 60, 180, 200]とすると、本形式は、次の計算式を用いて算出されます。
coco
cocoはCommon Object in Context COCO datasetのデータ形式です。本形式は[x_min, y_min, width, height]です。(x_min, y_min)はpascal_voc同様、バウンディングボックスの左上のピクセルを示し、width、heightはバウンディングボックスの横、縦の長さです。例としては[50, 60, 130, 140]です。
yolo
yoloは[x_center_norm, y_center_norm, width_norm, height_norm]と表現されます。(x_center_norm, y_center_norm)はバウンディングボックスの中心を示し、width, heightは横、縦の長さです。また、これら4つの値は正規化された値です。例としては、pascal_voc形式の[50, 60, 180, 200]で示されるバウンディングボックスは次の計算式を用いて変換されます。
上記4つの形式をまとめると以下になります。
pascal_voc:[x_min, y_min, x_max, y_max]
albumentations:[x_min_norm, y_min_norm, x_max_norm, y_max_norm]
coco:[x_min, y_min, width, height]
yolo:[x_center_norm, y_center_norm, width_norm, height_norm]
参考:https://albumentations.ai/docs/getting_started/bounding_boxes_augmentation/
学会
学会では直近の学会情報をお伝えします!今後は学会のレポートなども配信予定です!
スケジュール
直近で開催予定の人工知能系の学会

直近で終了した人工知能系の学会

書籍
ソフトウェア開発やビジネスに役立つ書籍を紹介します📖
具体と抽象 ―世界が変わって見える知性のしくみ
細谷 功 (著) dZERO (2014/11/27)
「抽象=知性」とする本書。抽象化思考を学びたい人、またすでに抽象に生きてはいるが具体的な表現しかできない人とのコミュニケーションギャップに悩む読者を対象に様々な説明をくれる一冊。
AIは出てこないが、重なって面白い。
サンプルを見て分布を学ぶ人工知能はまさに具体を抽象化する知的な仕掛けと言える。 抽象化の産物である「アナロジー(類推)」は抽象レベルの真似であり、具体の盗用であるパクリとは異なる点を指摘。これは拡散モデルなどの現代のAIの著作権の議論にも通じる。
自分の中に毒を持て<新装版>
岡本 太郎 (著) 青春出版社; 新装版 (2017/12/9)
一見厳しくも情熱と真実に溢れる熱い言葉に生きる力をもらえます。元気が欲しいときや迷ったときに開く一冊。