
週刊エーアイElith: Issue #22
YOLO系の歴史を解説

週刊エーアイElithでは、株式会社Elith(エリス)によって運用される日々の機械学習のニュース・OSS・研究・技術・学会・国内外AI企業の情報を毎週月曜日に配信するニュースレターです。 ニュースレターのコンセプトや概要、対象者、読み方については下の記事をご覧ください👍
AIニュース
AIニュースでは1週間でトレンドとなったニュースを紹介します。
2023年6月12日から2023年6月18日までのAIトレンドのニュースです。
AI資金関連ニュース
AI資金関連ニュースでは1週間でトレンドとなったニュースを紹介します。
2023年6月12日から2023年6月18日までのAIトレンドのニュースです。
論文
今週は物体検出で有名のモデルYOLOについて解説します。
YOLOとは?
YOLOとは、物体検出の代表的なアルゴリズムです。「You Only Look Once」という英文の頭文字からYOLOと名付けられました。「一度見るだけで良い」という意味で、人間のように一目見ただけで物体検出が可能です。特徴としては、文字通り推論速度が速く、リアルタイムの物体検出に向いています。
また、YOLOは2015年にv1が発表されてから改善が重ねられ、現在ではYOLOv8(2023年1月)まで登場しています。その一連のシリーズをまとめてYOLO系とも呼ばれています。
YOLO一覧
YOLOv1(2015/06)
YOLOv2(2016/12)
YOLOv3(2018/04)
YOLOv4(2020/04)
YOLOv5(2020/05)
YOLOX(2021/08)
YOLOv6(2022/06)
YOLOv7(2022/11)
YOLOv8(2023/01)
今週はYOLOv1〜v4までの解説を行い、次週以降でv5〜v8までの解説を行います。
歴史
この章では、2015年からYOLO系がどのように進化をしてきたのかを簡潔に解説します。
YOLOv1
YOLOは2015年に「You Only Look Once: Unified, Real-Time Object Detection」という論文で発表されました。ほぼ同時期にFast R-CNNが発表され、リアルタイムの物体検出のスタンダードとなりました。
YOLOv1の特徴
2段階で行われていた「検出」と「識別」を1段階の検出で行い、高速化(45fps)
End-to-Endモデル
精度が低い(Fast R-CNNと比較)
アーキテクチャ
YOLOv1では、3つの特徴があります。
①グリッドセル(grid cell)に分割
YOLOv1では、入力画像をS*Sのグリッドセルに分割します(以下はS=7の例)。物体の中心がグリッドセルにある場合、そのグリッドセルが物体を検出するように学習します。

参照:https://arxiv.org/abs/1506.02640
②物体の予測
YOLOv1では、B個の物体検出、C個のクラスの予測を行う出力層は以下のようになります
信頼スコア(B個)
BBOX(B個)
クラス確率(C個)
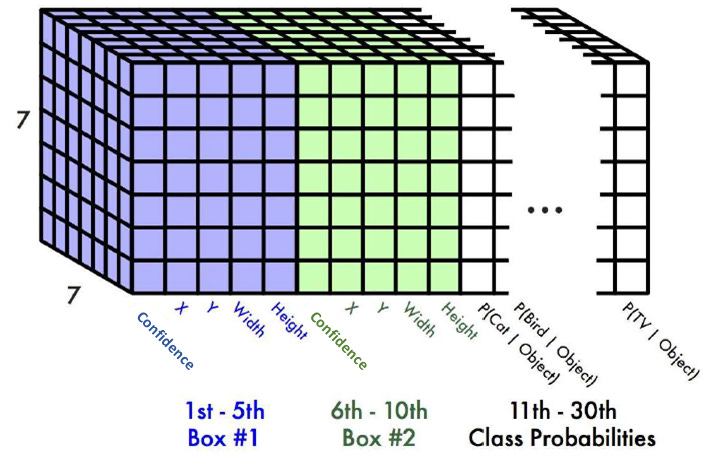
参照:https://arxiv.org/abs/1506.02640
③Darknet
YOLO v1では、24層のCNNと4層のPooling層、2つの全結合層から出力層を計算します。

参照:https://arxiv.org/abs/1506.02640
YOLOv2
YOLO v2は、2016年に「YOLO9000: Better, Faster, Stronger」という論文で発表されています。この論文ではYOLOv2とYOLO9000という二つのモデルが提案されています。YOLOv2はYOLOv1を改良したもので、YOLO9000は9000クラスの分類が可能なモデルとして提案されています。
YOLOv2の特徴は以下の通りです。
Batch Normalizationの導入
High Resolution Classifierの導入
領域分類
Darknet-19の導入
領域分類とは、アンカーボックスが手動で作成されていることに問題意識を持ち、K-means分類で学習用のBBOXを作成しました。
また、Darknet-19では、19層のCNNと5層のPooling層に変更し高速化しました。

参照:https://arxiv.org/abs/1612.08242
YOLOv3

YOLOv3は、2018年に「YOLOv3: An Incremental Improvement」という論文で発表されました。YOLOv3では、精度の高いYOLOv3-416(mAP:55.3)と、高速化した軽量モデルYOLOv3-tiny(mAP:33.1)が公開されています。
改善点は主に2つです。
1つ目は、スケール間予測です。異なるスケールで画像を予測するためにFeature Pyramid Networks(FPN)モデルを採用しています。特徴量マップは前の2つから取得し、2倍にアップサンプリングされます。出力層は、異なるスケールから出力層を計算するため、画像の大小両方を考慮した物体検出が可能となりました。
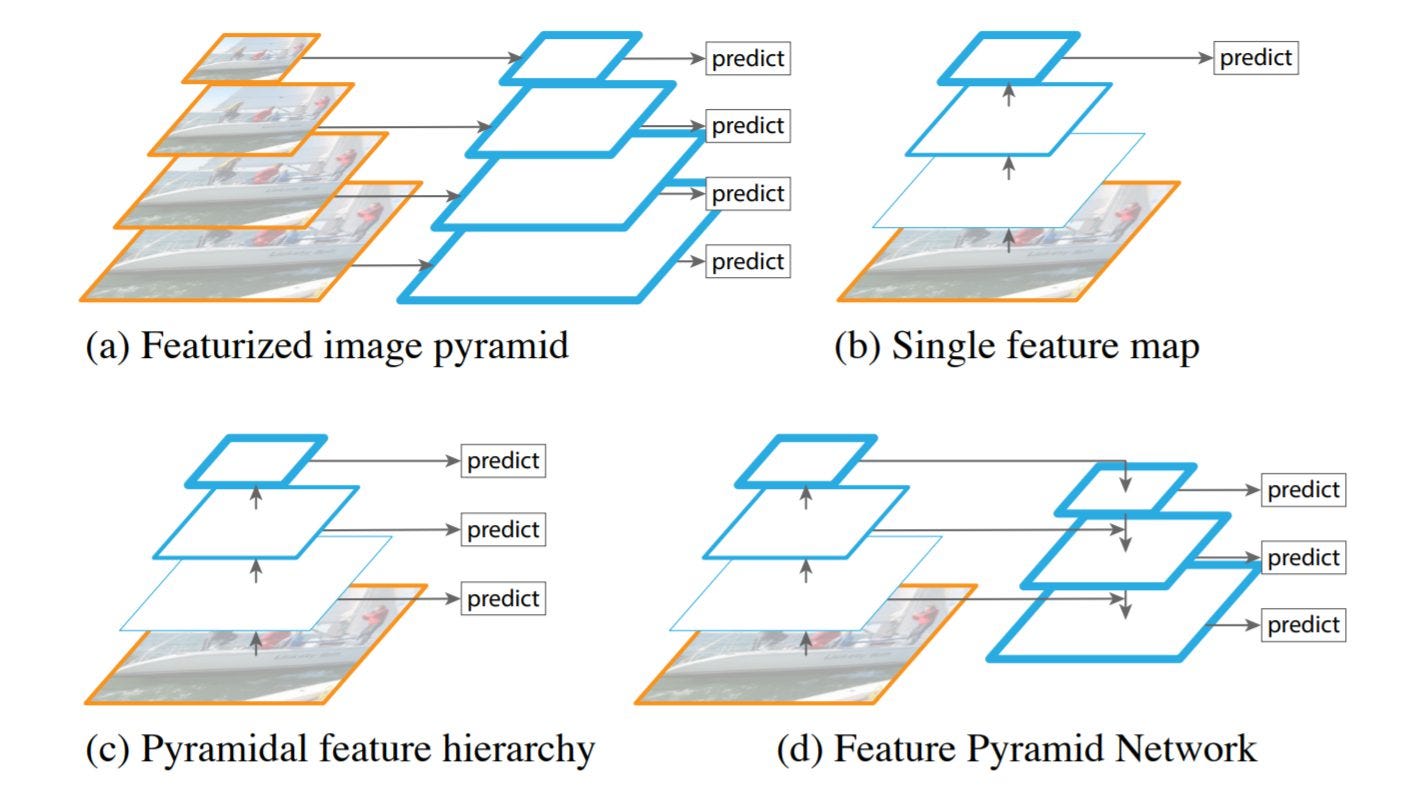
参照:https://arxiv.org/abs/1804.02767
2つ目は、Darknet-53を用いたアーキテクチャーです。53層のCNNを導入しました。全結合層を使用しないため、入力画像サイズは任意となっています。
YOLOv4
YOLOv4からは著者が変わり「YOLOv4: Optimal Speed and Accuracy of Object Detection」という論文で公開されています。
YOLOv4の特徴としては、YOLOv3までで提案されているバックボーン、ネック、ヘッドを総当たりで学習させ、一番精度の良いモデルを探索した点です。結果としては、バックボーンにCSPDarknet-53、ネックにPAN/SPP、ヘッドにYOLOv3を用いたモデルが一番精度が高くなりました。
CSPDarknet-53とは、前述のDarknet-53にCSPnetという精度を落とさずに高速化をする手法が採用されたものです。PANはPFNに層を追加し、より正確な位置が検出できるようになったモデルです。SSPは色々なスケールの物体検出が可能になる機能です。
また細かい機能としては、検出速度を落とさずに精度を上げる機能と、検出の速度は遅くなるが精度を上げる機能がいくつか搭載されています。
検出速度を落とさずに精度を上げる機能
CutMix
SAT (Self-Adversarial Training)
DropBlock正則化
CIoU損失
Class label smoothing
CmBN
Mosaic data augmentation
Eliminate grid sensitivity
Cosine annealingスケジューラー
Random training shapes
検出の速度は遅くなるが精度を上げる機能
Mish
Cross-stage partial connections (CSP)
Multi-input weighted residual connections (MiWRC)
SPP Block
SAM Block
PAN(path-aggregation block)
DIoU-NMS
これらの複雑な機能が搭載された集合体がYOLOv4です。
まとめ
今週はYOLOv4までの紹介を行いました。YOLOv1では、1度のフローで物体検出ができるモデルを提案し、YOLOv2でアンカーボックスの改善、YOLOv3では、バックボーンの改善が行われました。YOLOv4では、既存のモデルの組み合わせで一番精度の高いものを実験し、さらに細かい修正を加えることで精度の改善を計りました。
次週YOLOXからYOLOv8までのモデルの紹介を行います。