

週刊エーアイElithでは、株式会社Elith(エリス)によって運用される日々の機械学習のニュース・OSS・研究・技術・学会・国内外AI企業の情報を毎週月曜日に配信するニュースレターです。 ニュースレターのコンセプトや概要、対象者、読み方については下の記事をご覧ください👍
AIニュース
AIニュースでは1週間でトレンドとなったニュースを紹介します。
2023年6月19日から2023年6月27日までのAIトレンドのニュースです。
AI資金関連ニュース
AI資金関連ニュースでは1週間でトレンドとなったニュースを紹介します。
2023年6月19日から2023年6月27日までのAIトレンドのニュースです。
論文
今週は先週に引き続き物体検出で有名のモデルYOLOについて解説します。
先週のYOLOv1〜v4までの解説は以下の記事を参照ください。
週刊エーアイElith: Issue #22

週刊エーアイElithでは、株式会社Elith(エリス)によって運用される日々の機械学習のニュース・OSS・研究・技術・学会・国内外AI企業の情報を毎週月曜日に配信するニュースレターです。 ニュースレターのコンセプトや概要、対象者、読み方については下の記事をご覧ください👍 AIニュース AIニュースでは1週間でトレンドとなったニュースを紹介します。 2023年6月12日から2023年6月18日までのAIトレンドのニュースです。 OpenAIを追うジェネレーティブAI市場の注目株。グーグルもジェネレーティブAIスタートアップに多額の投資
YOLO一覧
YOLOv1(2015/06)
YOLOv2(2016/12)
YOLOv3(2018/04)
YOLOv4(2020/04)
YOLOv5(2020/05)
YOLOX(2021/08)
YOLOv6(2022/06)
YOLOv7(2022/11)
YOLOv8(2023/01)
今週はYOLOv5〜v8までの解説を行います。
YOLOv5
github:https://github.com/ultralytics/yolov5
特徴
YOLOv5の特徴としては、以下の3つが挙げられます。
推論速度の高速化
最適化のハイパーパラメータの追加
object tracking、Segmentation、Classificationの実装
モデルの様々な形式への変換
モデルのbackborneは、yolov4と大きく変わりません。ConvとBottleneckCSPを複数層利用することで特徴を抽出します。
以下にyolov5sのバックボーンの概要を記載します。
最初のレイヤーは、入力画像のサイズを半分に縮小するための畳み込みレイヤー(Conv)です。このレイヤーは、64チャネルの畳み込みフィルタを使用し、ダウンサンプリングを行います。出力はP1/2と呼ばれる特徴マップです。
次のレイヤーは、P1/2の特徴マップを入力として、さらにダウンサンプリングを行います。Convが使用され、128チャネルの畳み込みが適用されます。出力はP2/4と呼ばれる特徴マップです。
さらに、C3(BottleneckCSP)と呼ばれるモジュールが3回繰り返されます。C3は、入力特徴マップを2つの異なるパスに分割し、それぞれを畳み込みレイヤーで処理し、最後に結合します。
その後、ストライド2の畳み込みレイヤーが適用され、P3/8と呼ばれる特徴マップが生成されます。
さらに、C3が6回繰り返されます。
ストライド2の畳み込みレイヤーが適用され、P4/16と呼ばれる特徴マップが生成されます。
C3が9回繰り返され、さらに特徴の抽出が行われます。
最後に、ストライド2の畳み込みレイヤーが適用され、P5/32と呼ばれる特徴マップが生成されます。
1.推論速度の高速化
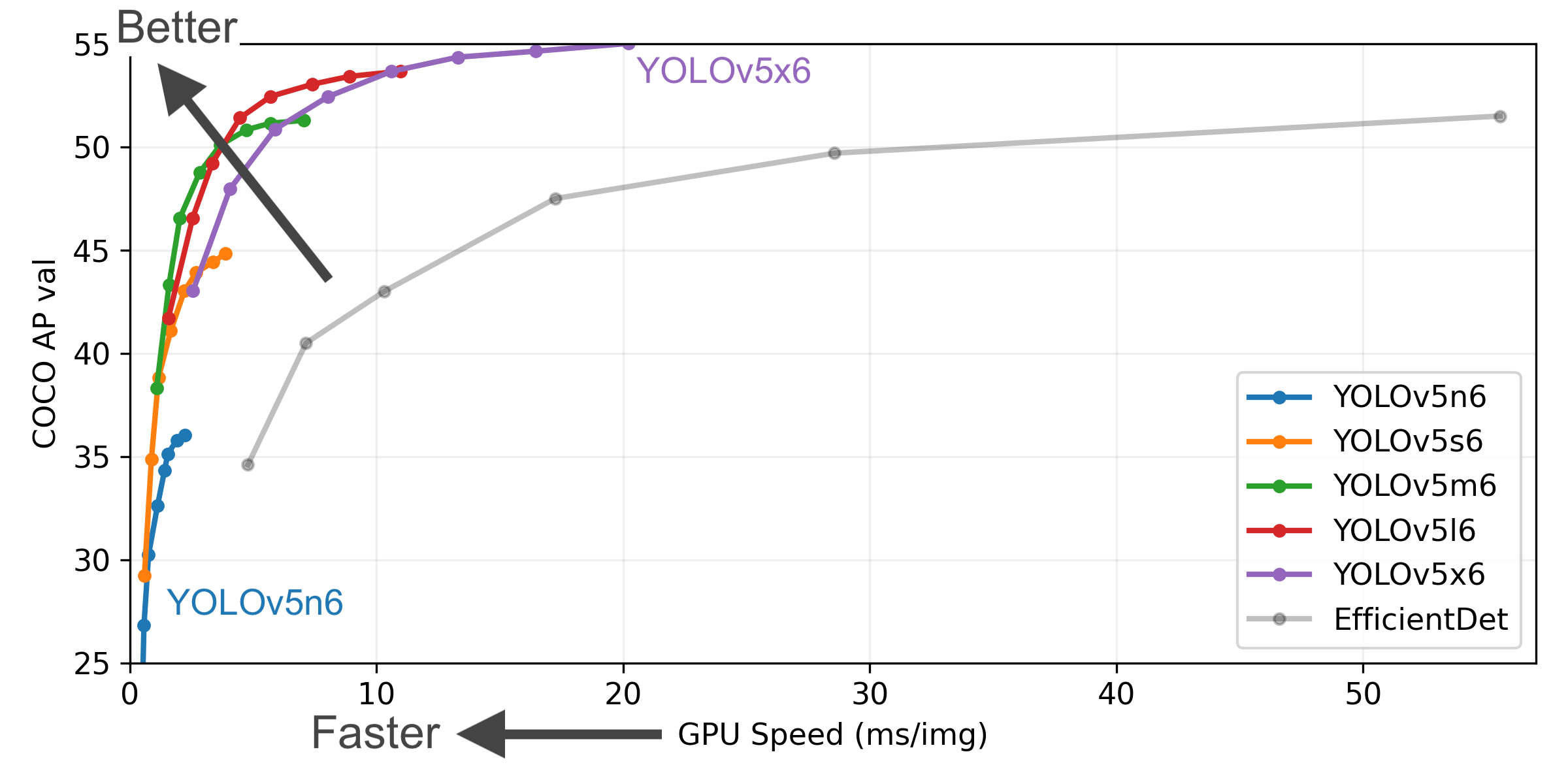
YOLOv5では1画像10ms程度で55APと、高速な実行速度で高い検出精度です。
2.最適化のハイパーパラメータの追加
YOLOv5では複数のハイパーパラメータが存在します。以下にその例を記載します。
# YOLOv5 Hyperparameter Evolution Results
# Best generation: 287
# Last generation: 300
# metrics/precision, metrics/recall, metrics/mAP_0.5, metrics/mAP_0.5:0.95, val/box_loss, val/obj_loss, val/cls_loss
# 0.54634, 0.55625, 0.58201, 0.33665, 0.056451, 0.042892, 0.013441
lr0: 0.01 # initial learning rate (SGD=1E-2, Adam=1E-3)
lrf: 0.2 # final OneCycleLR learning rate (lr0 * lrf)
momentum: 0.937 # SGD momentum/Adam beta1
weight_decay: 0.0005 # optimizer weight decay 5e-4
warmup_epochs: 3.0 # warmup epochs (fractions ok)
warmup_momentum: 0.8 # warmup initial momentum
warmup_bias_lr: 0.1 # warmup initial bias lr
box: 0.05 # box loss gain
cls: 0.5 # cls loss gain
cls_pw: 1.0 # cls BCELoss positive_weight
obj: 1.0 # obj loss gain (scale with pixels)
obj_pw: 1.0 # obj BCELoss positive_weight
iou_t: 0.20 # IoU training threshold
anchor_t: 4.0 # anchor-multiple threshold
# anchors: 3 # anchors per output layer (0 to ignore)
fl_gamma: 0.0 # focal loss gamma (efficientDet default gamma=1.5)
hsv_h: 0.015 # image HSV-Hue augmentation (fraction)
hsv_s: 0.7 # image HSV-Saturation augmentation (fraction)
hsv_v: 0.4 # image HSV-Value augmentation (fraction)
degrees: 0.0 # image rotation (+/- deg)
translate: 0.1 # image translation (+/- fraction)
scale: 0.5 # image scale (+/- gain)
shear: 0.0 # image shear (+/- deg)
perspective: 0.0 # image perspective (+/- fraction), range 0-0.001
flipud: 0.0 # image flip up-down (probability)
fliplr: 0.5 # image flip left-right (probability)
mosaic: 1.0 # image mosaic (probability)
mixup: 0.0 # image mixup (probability)
copy_paste: 0.0 # segment copy-paste (probability)ただし、個別に設定する必要はなく、—evolveを設定することで自動で最適化することが可能です。
python train.py --evolve 1000また、utils.plots.plot_evolve()を使用してハイパーパラメータの更新の様子を可視化することも可能です。

3.object tracking、Segmentation、Classificationの実装
こちらは詳しくは解説しませんが、YOLOv5を使用して様々なタスクを簡単に実行することができます。
また、GPLライセンス v3.0で商用利用可能です。まずモデルを試したい時などはYOLOv5から始めるのが良いのではないでしょうか。
4.モデルの様々な形式への変換
YOLOv5で学習したモデルは、以下の様々な形式に変換が可能です。

参照:https://docs.ultralytics.com/yolov5/tutorials/model_export/#before-you-start
YOLOX
YOLOxは、2021年のCVPR2021のAutomous Driving WorkshopのStreaming Perception Challengeで1位を獲得したモデルです。
github:https://github.com/Megvii-BaseDetection/YOLOX
特徴
YOLOXの特徴は以下の通りです。
従来のYOLOをアンカーフリーに変更
Decoupled HeadとSimOTAを導入
ライセンスがApache License 2.0
強力なデータ拡張の利用
1.従来のYOLOをアンカーフリーに変更
従来のYOLOモデルでは(YOLOv3を除く)、アンカーボックスという予め中心と縦横比が決められた短径のテンプレートを使用していました。一つの特徴マップから複数のアンカーを予測していました。直接BBOXを計算する必要がありませんでした。しかし、事前定義されたBBOXのサイズに合わない物体を正確に検出できないこと、アンカーの設計次第ではパラメータが大きくなってしまうことが課題でした。
アンカーフリーとは、一つの特徴マップから直接BBOXの幅と高さを予測する手法です。特徴マップの各点に関して、一つの物体のground truthのBBOXに含まれる場合は、ポジティブサンプル、複数のground truthのBBOXに含まれる場合は、アンビギュアスサンプルとします。
アンカーボックス法では、特徴マップの各点にn個のサンプル(アンカーボックス)を計算するのに対して、アンカーフリーでは、各点に1個のサンプル(ポジティブサンプルorアンビギュアスサンプル)として計算します。そのため、サンプル数を大幅に減らすことができ、学習速度を1/n倍に改善することが可能です。

参照:https://medium.com/lsc-psd/fcos-アンカーフリー物体検出法-dd18147dc822
2.Decoupled HeadとSimOTAを導入
従来のYOLOシリーズのbackboneとfeature pyramidsにはCoupled headが使用されてました。YOLOXでは、YOLOシリーズのCoupled headをDecoupled headに置き換えることで高精度化を行っています。
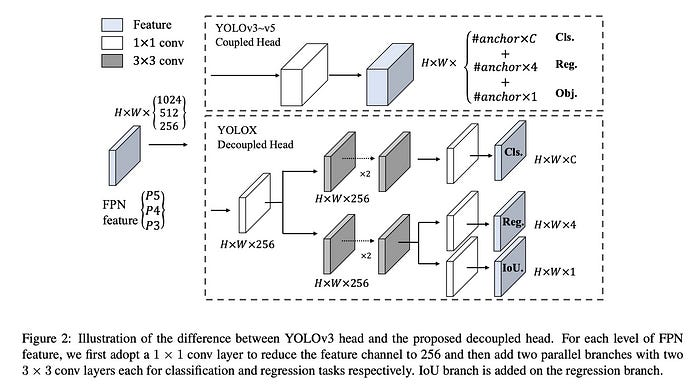
また、Lossの最適化にはOTA(Optimal Transport)を改良したSimOTAを使用しています。
上記の画像例のように、複数の物体を含むサンプルでは、予測したBBOXをどのground truthに割り当てるのかという割り当て問題が発生します。
これは、OTAと呼ばれる最適輸送問題として定式化されています。しかし、OTAを計算するには、Shinkhorm-Knoppアルゴリズムを用いるため、学習時間がおよそ25%増加します。
そこでYOLOXでは、OTAをシンプルにしたSimOTAを採用しています。どのground truthに割り当てるのかの分類損失とBBOXの大きさの回帰損失のバランスをとるLOSS関数です。
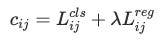
参照:https://zenn.dev/takoroy/articles/e1e401b865f6c1#simota
3.ライセンスがApache License 2.0
YOLOシリーズで唯一のApache Licenseです。GPLの利用ができないシーンではYOLOXの利用を考えると良いでしょう。
4.強力なデータ拡張の利用
YOLOXでは、MosaicとMixUpという二つの強力なデータ拡張を取り入れています。
Mosaic
以下のように複数の画像を組み合わせるデータ拡張です。

参照:https://zenn.dev/takoroy/articles/e1e401b865f6c1#strong-augumentation
MixUp
以下の図のように2枚の画像を重ね合わせた確率値を予測するデータ拡張です。

YOLOv6
YOLOv6は2022年9月に公開されました。
github:https://github.com/meituan/YOLOv6
性能を落とさずに推論速度を向上させることを目標に設計されています。
現在はYOLOv6(3.0)が2023年1月に公開されており、YOLOv8よりも高い性能を持っています。今回はYOLOシリーズの歴史を振り返るという視点でオリジナルのモデルを解説します。YOLOv6(3.0)が気になる方は以下を参照ください。
YOLOv6(3.0):https://arxiv.org/abs/2301.05586
特徴
YOLOv6は以下のような特徴があります。
モデルアーキテクチャの改善
損失関数の改善
1.モデルアーキテクチャの改善
YOLOv6では、バックボーン、ネック、ヘッドの全てを改良しています。

バックボーン
まず、バックボーンについてですが、RepVGG blockとRepConvを利用しています。これは学習と推論でネットワーク構造が変化します 。
左側がRepVGG blockを利用した学習で、右側がRepConv(3×3 畳み込み)を利用した推論です。
このバックボーン全体をEfficientRepと呼びます。

ネック
YOLOv6では、PAN (Path Aggregation Networks)を利用しています。これ自体は他のYOLOシリーズでも利用していますが、YOLOv6では、再パラメータ化された様々なblockを利用する点からreparameterized PANやRep-PANと呼ばれています。
ヘッド
YOLOv6では、他のYOLOシリーズでは使われていなかったEfficient Decoupled Headを利用しています。

これは、分類と検出でパラメータを共有せずに、別々に計算を行います。これにより、計算量を減らし、高い精度を出すことが可能になりました。
2.損失関数の改善
YOLOv6では、2つの損失関数を定義しています。
分類:VFL (Varifocal Loss)
ボックス回帰:DFL (Distribution Focal Loss) along with SIoU or GIoU
ここでは詳細な説明は省略しますが、興味のある方は以下をご参照ください。
VFL:https://paperswithcode.com/method/varifocal-loss
DFL:https://arxiv.org/abs/2006.04388
YOLOv7
YOLOv7は、YOLOv4と同じChien-Yao Wang, Alexey Bochkovskiy, Hong-Yuan Mark Liaoによる開発です。
YOLOv7でも実行速度、精度がどちらも大きく改善しています。
github:https://github.com/WongKinYiu/yolov7
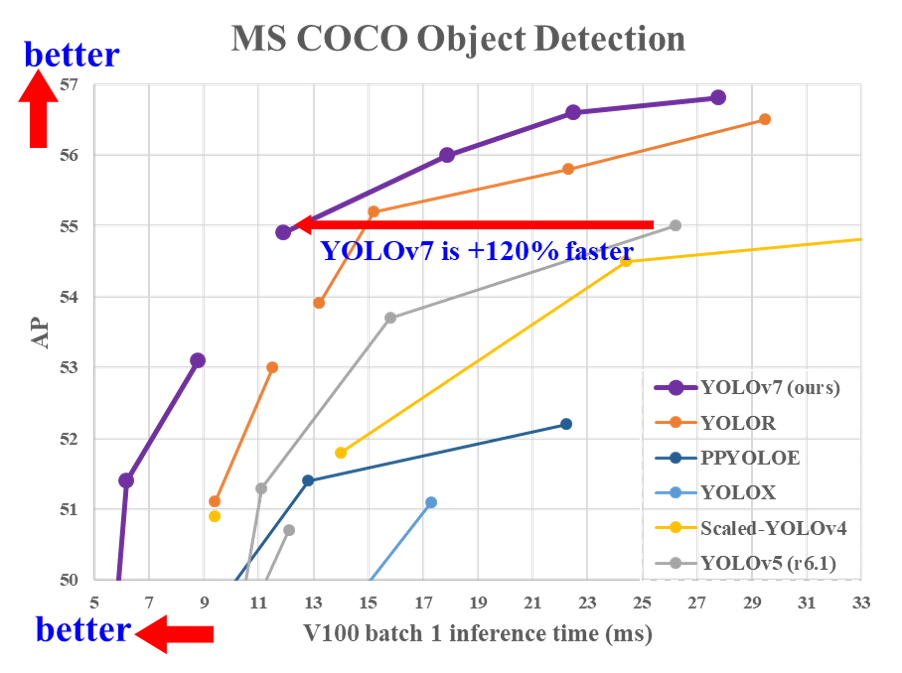
特徴
YOLOv7では以下のような特徴があります。
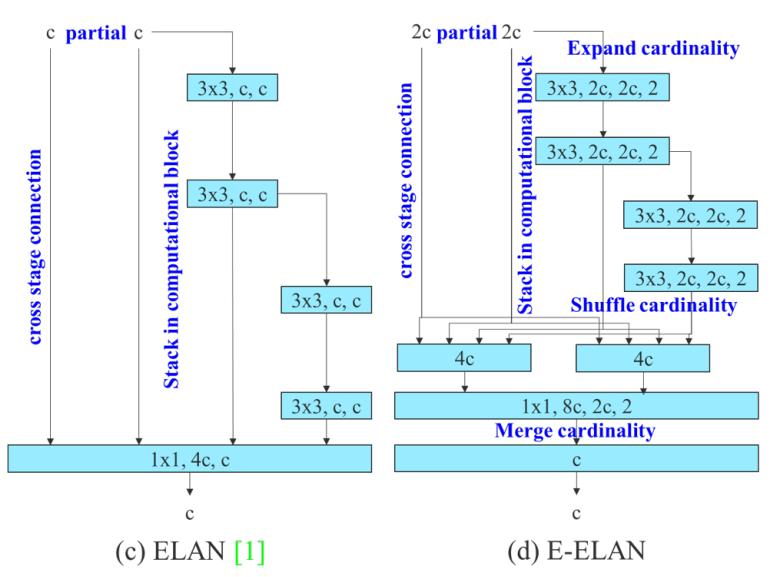
アーキテクチャにELAN, E-ELANを使用
concatenateモデルに適した複合スケーリング方法
ラベル割り当て戦略
1.アーキテクチャにELAN, E-ELANを使用
YOLOv7は、ピラミッド型の構造をしています。ピラミッドの深層に変換する際に以下のELAN、E-ELANが利用されています。
ELANでは、一度のConvではなく、左側のように複数の小さいConvを組み合わせることでパラメータ数を落としています。これにより精度を落とさずに実行速度を改善することが可能となっています。
E-ELANではさらに複雑にConvが取り入れられています。こちらはYOLOv7-E6Eにのみ使用されています。
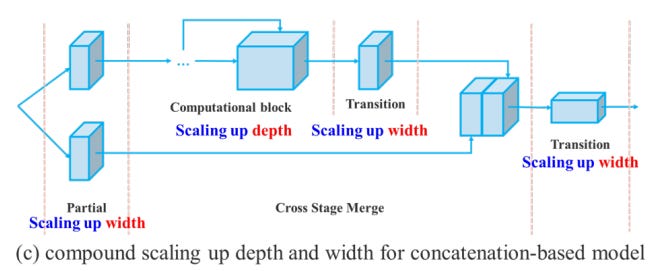
2.concatenateモデルに適した複合スケーリング方法
通常のスケーリング(a→b)では、depthを増やすと同時にwidthも増加します。

YOLOv7では、depthを増やして、widthのスケーリングを抑える手法を導入しています。depthのファクターはcomputational blockを変化させるファクターとして考え、computational block以外の畳み込みのノード数をwidthにより変化させるファクターとして、複合スケーリングを提案しています。実際には、depthを1.5倍するのに対してwidthを1.25倍にするという倍率でスケールさせています。
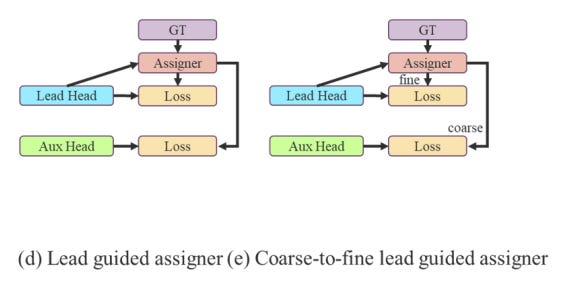
3.ラベル割り当て戦略
YOLOv7では、Auxiliary Lossを採用しています。
Auxiliary Lossとは、モデルのアーキテクチャの中間層の出力を用いて、推論を行う手法です。

YOLOv7では、Auxiliary Lossを改善しました。
(d)では、Aux HeadとLead Head双方にLead Headの割り当て結果を使用します。
(e)では、Aux Head側のソフトラベルをより緩和して多くの正例を扱えるように改良しました。
この結果、Aux Head側の学習精度が向上し、Recallの改善につながっています。
YOLOv8
最後にYOLOv8について解説します。
github:https://github.com/ultralytics/ultralytics
YOLOv8では、言わずもがな、既存のYOLOシリーズよりも高い性能を持っています。
YOLOv5と同じultralyticsという会社で開発されています。
YOLOv8はYOLOv5同様に論文が公開されていませんが、可能な限り解説を行います。
特徴
YOLOv8は以下の特徴があります。
物体検出、セグメンテーション、キーポイント、トラッキング、分類が可能
YOLOv5からモデルのアーキテクチャの改善
1.物体検出、セグメンテーション、キーポイント、トラッキング、分類が可能
YOLOv8は会社が運営元ということもあり、様々なタスクで利用できる形で学習済みモデルが公開されています。
2.YOLOv5からモデルのアーキテクチャの改善
以下の図は公式ではありませんが、RangeKing氏により公開されているYOLOv8のアーキテクチャです。

参照:https://github.com/ultralytics/ultralytics/issues/189
ここから読み取れるYOLOv5との違い以下の通りです。
C3をC2fに変更
バックボーンの6×6 Convを3×3 Convに変更
No.10とNo.14のConvを削除
Bottleneckの1×1 Convを3×3 Convに変更
decoupled headの採用
objectnessを削除
Conclusion
以上が、YOLOv5〜v8までのモデルについて解説を行いました。前回のYOLOv1から振り返ると物体検出のモデルがどのように改善されていったのか全体像を把握することができたと思います。今後も新しいYOLOシリーズが登場する際は、歴史を振り返ることでどのような改善が行われたのかをクリアに理解ができるようになったと思います。